
Der Miller-Rabin-Test ist eine Verschärfung des Fermat-Tests und dient ebenfalls der Bestimmung von Primzahlen ( ). Dieser hat allerdings im Vergleich zum Fermat-Test eine wesentlich höhere Trefferwahrscheinlichkeit in Bezug auf die Bestimmung von Primzahlen.
). Dieser hat allerdings im Vergleich zum Fermat-Test eine wesentlich höhere Trefferwahrscheinlichkeit in Bezug auf die Bestimmung von Primzahlen.
Beim Miller-Rabin-Test handelt es sich um einen probilistischen Primzahltest. Dies bedeutet, dass die Basis  auf welcher die Exponentation durchgeführt wird zufällig innerhalb des Intervalls
auf welcher die Exponentation durchgeführt wird zufällig innerhalb des Intervalls ![]1, \ p-1] \in \mathbb{Z}](https://schmidtj.lima-city.de/wp-content/ql-cache/quicklatex.com-6e1f3bfe80777047771597bd0120c69b_l3.png "Rendered by QuickLaTeX.com") gewählt wird. Anders als beim Fermat-Test werden beim Miller-Rabin-Test mehrere Basen als sogenannte Zeugen verwendet.
gewählt wird. Anders als beim Fermat-Test werden beim Miller-Rabin-Test mehrere Basen als sogenannte Zeugen verwendet.
Eine Basis gilt als Belastungszeuge für , wenn  ist, aber
ist, aber  und
und  .
.
Die Begründung hierfür ist folgende:
Ist eine Primzahl, dann ist  ein Körper. In einem mathematischen Körper hat jede quadratische Gleichung höchstens zwei unterschiedliche Lösungen. Nun hat aber in die quadratische Gleichung
ein Körper. In einem mathematischen Körper hat jede quadratische Gleichung höchstens zwei unterschiedliche Lösungen. Nun hat aber in die quadratische Gleichung  schon die beiden Lösungen
schon die beiden Lösungen  und
und  . Da
. Da  vorausgesetzt werden kann, sind diese auch verschieden. Gibt es nun noch eine weitere Lösung, dann kann kein Körper sein. Dann kann auch keine Primzahl sein.
vorausgesetzt werden kann, sind diese auch verschieden. Gibt es nun noch eine weitere Lösung, dann kann kein Körper sein. Dann kann auch keine Primzahl sein.
Beispiel:
Vermutete Primzahl 
Ausgehend vom Satz von Fermat: 
 wird solange durch zwei dividiert bis ein ungerader Wert
wird solange durch zwei dividiert bis ein ungerader Wert  entsteht:
entsteht:
36 : 2 = 18
18 : 2 = 9
Diese Werte  werden anschleißend in eine Tabelle eingetragen und die Berechnungen
werden anschleißend in eine Tabelle eingetragen und die Berechnungen  durchgeführt. Die Basis für die Exponentation liegt im Intervall
durchgeführt. Die Basis für die Exponentation liegt im Intervall ![]1, \ p-1]](https://schmidtj.lima-city.de/wp-content/ql-cache/quicklatex.com-e5dbf932d491aaa9e322cf13c5a0008c_l3.png "Rendered by QuickLaTeX.com") .
.
|  |  |  |
| 5 | 6 | 36 | 1 |
| 12 | 1 | 1 | 1 |
| 15 | 31 | 36 | 1 |
Aus den 1-sen in der letzten Spalte kann nun geschlossen werden, dass es sich bei  mit hoher Wahrscheinlichkeit um eine Primzahl handelt.
mit hoher Wahrscheinlichkeit um eine Primzahl handelt.
Mit Hilfe der Programmiersprache Python, kann der Miller-Rabin-Test wie folgt beschrieben werden:
from random import randint
def millerRabin(prim):
tmp = prim - 1
wPrim = True
i = 0
while i < 20:
basis = randNumber(tmp)
while tmp % 2 == 0:
if basis**tmp % prim == 1:
wPrim = True
break
else:
wPrim = False
tmp = tmp // 2
if not wPrim:
break
i += 1
if wPrim:
print("wahrscheinlich Primzahl.")
else:
print("Keine Primzahl.")
def randNumber(wert):
return randint(2, wert)
def isgerade(zahl):
if zahl == 2:
print("wahrscheinlich Primzahl.")
elif zahl % 2 == 0 and zahl > 2:
print("Keine Primzahl.")
else:
if millerRabin(zahl):
print("wahrscheinlich Primzahl.")
else:
print("Keine Primzahl")
if __name__ == '__main__':
prim = 561
isgerade(prim)Im obigen Programm wird, anders als beim Fermat-Test, die 561 (Pseudoprimzahl) als nicht Primzahl durch den Miller-Rabin-Test erkannt. Um ein besseres Laufzeitverhalten zu gewährleisten, kann die Anzahl der Schleifendurchläufe und die Anzahl der zu testenden Basen reduziert werden. Dies geht allerdings auf Kosten der Treffergenauigkeit. Man sollte demzufolge eine gute Balance zwischen Treffergenauigkeit und Laufzeitverhalten finden.
 ist folgende
ist folgende 
 .
. ) zerlegen. Hierbei handelt es sich um eine sogenannte Pseudoprimzahl zur Basis 2 bezüglich des Fermat-Tests (genauer gesagt ist die 561 die kleinste Carmichael-Zahl). In der Praxis spielt daher der Fermat-Test, wegen seiner nicht ausreichenden genauen Bestimmung von Primzahlen keine oder kaum eine Rolle.
) zerlegen. Hierbei handelt es sich um eine sogenannte Pseudoprimzahl zur Basis 2 bezüglich des Fermat-Tests (genauer gesagt ist die 561 die kleinste Carmichael-Zahl). In der Praxis spielt daher der Fermat-Test, wegen seiner nicht ausreichenden genauen Bestimmung von Primzahlen keine oder kaum eine Rolle. ) zweier natürlicher Zahlen zu ermitteln. Das Ermitteln des
) zweier natürlicher Zahlen zu ermitteln. Das Ermitteln des  und
und  der
der  ermittelt werden.
ermittelt werden. (
( steht hierbei für den Rest der ganzahligen Division).
steht hierbei für den Rest der ganzahligen Division).




 abgelesen werden (fett gedruckte 3). Die Berechnung des
abgelesen werden (fett gedruckte 3). Die Berechnung des  auch in Form einer Tabelle ermittelt werden:
auch in Form einer Tabelle ermittelt werden: zu lösen. Vielfache des
zu lösen. Vielfache des  sind ebenfalls lösbar und können allgemein mit
sind ebenfalls lösbar und können allgemein mit  für
für  beschrieben werden.
beschrieben werden. 




 und
und  und
und  . Die Spalte r spielt bei der Berechnung von
. Die Spalte r spielt bei der Berechnung von  und
und 



 und
und  eingetragen und
eingetragen und


 wie folgt ermitteln:
wie folgt ermitteln: dar.
dar.
 (
( sind teilerfremd).
sind teilerfremd). :
: 
 mit
mit 

 (da 2 teilerfremd zu
(da 2 teilerfremd zu 
 und aller
und aller 


 . Praktische Anwendung findet er u.a. in der Kryptographie beispielsweise beim RSA-Verschlüsselungsverfahren.
. Praktische Anwendung findet er u.a. in der Kryptographie beispielsweise beim RSA-Verschlüsselungsverfahren.  (also wenn
(also wenn  (
( :
:
 von
von  genau ein
genau ein  gibt, so dass
gibt, so dass (1)
(1) und
und  (2)
(2) sein. Auf Grund dessen, kann durch
sein. Auf Grund dessen, kann durch 
 ist daher
ist daher  im Widerspruch zu
im Widerspruch zu  können nun mit
können nun mit 
 und die Primzahl
und die Primzahl  dividiert werden und man erhält die obige Behauptung.
dividiert werden und man erhält die obige Behauptung. , so kann die
, so kann die  jeder natürlichen Zahl ungleich null nicht in die Summe zweier
jeder natürlichen Zahl ungleich null nicht in die Summe zweier  natürlicher Zahlen ungleich null zerlegt werden.
natürlicher Zahlen ungleich null zerlegt werden.
 unlösbar wenn
unlösbar wenn  kongruent
kongruent  , wenn sie bei der Division durch
, wenn sie bei der Division durch  denselben Rest haben. Dies ist genau dann der Fall, wenn sie sich um ein ganzahliges Vielfaches von
denselben Rest haben. Dies ist genau dann der Fall, wenn sie sich um ein ganzahliges Vielfaches von  ; da
; da  und
und  ist.
ist. ; da
; da  und
und  ist.
ist.  ; da
; da  und
und  ist.
ist. kann wie folgt implementiert werden:
kann wie folgt implementiert werden: -Funktion gibt für jede natürliche Zahl
-Funktion gibt für jede natürliche Zahl  dabei bezeichnet
dabei bezeichnet  den größten gemeinsamen Teiler von
den größten gemeinsamen Teiler von  .
. denn in der Menge
denn in der Menge  sind nur die Zahlen 1, 5, 7, 11 teilerfremd.
sind nur die Zahlen 1, 5, 7, 11 teilerfremd. da 13 eine Primzahl ist, sind alle Zahlen die kleiner sind als 13 teilerfremd.
da 13 eine Primzahl ist, sind alle Zahlen die kleiner sind als 13 teilerfremd. gilt:
gilt:  .
.  . Dann gilt:
. Dann gilt: 

 relativ einfach wie folgt implementieren:
relativ einfach wie folgt implementieren: .
1) Berechne den ganzzahligen Quotienten
.
1) Berechne den ganzzahligen Quotienten  von
von  .
3) Gebe
.
3) Gebe  und
und  mit
mit  .
.


 bezeichnet. Mit
bezeichnet. Mit  der nach ihrer Größe geordneten Primzahlen, die man auch Primzahlfolge nennt.
der nach ihrer Größe geordneten Primzahlen, die man auch Primzahlfolge nennt. 
 und
und  .
3) Dann wählt Sie
.
3) Dann wählt Sie  mit
mit  .
4) Alice bestimmt
.
4) Alice bestimmt  mit
mit  .
5) Dann ist
.
5) Dann ist  der öffentliche und
der öffentliche und  der geheime Schlüssel.
6) Die Werte
der geheime Schlüssel.
6) Die Werte  und
und  löscht Alice.
löscht Alice. schicken. Er geht nun wie folgt vor:
schicken. Er geht nun wie folgt vor: und schickt
und schickt  .
. ?
? (Division mit Rest) angewendet ?
(Division mit Rest) angewendet ? .
. zu berechnen. Demnach wären
zu berechnen. Demnach wären  Multiplikation notwendig.
Multiplikation notwendig.

 b ins Binärsystem zu überführen:
b ins Binärsystem zu überführen:
 und multipliziert ein
und multipliziert ein  zum Endergebnis wenn
zum Endergebnis wenn  . Daraus ergibt sich eine höchste Anzahl an Multiplikationen von
. Daraus ergibt sich eine höchste Anzahl an Multiplikationen von  .
.
 :
:
 mit
mit  beschrieben werden:
beschrieben werden: 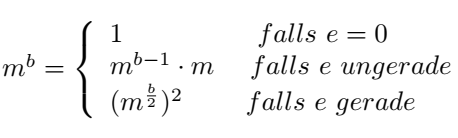
 in Python mit dem Rückgabewert als Ergebnis 1:
in Python mit dem Rückgabewert als Ergebnis 1: (für
(für  ) beträgt
) beträgt  lineares Laufzeitverhalten.
lineares Laufzeitverhalten. wobei
wobei  wird
wird  immer mit einer 1 beginnt und damit auch die erste Anweisung mit QM, ergibt sich hierfür
immer mit einer 1 beginnt und damit auch die erste Anweisung mit QM, ergibt sich hierfür  .
. und
und  .
. die führende 1 wird nun gestrichen
die führende 1 wird nun gestrichen  Q
Q  QM
QM Q
Q QM
QM